背景
随着业务的复杂性增长,现在很多程序同时包含 cpu 代码和 gpu 代码。
一个典型场景为:cpu 读取远程数据,转换成 gpu 算子处理格式,运行 gpu 算子,拿到 gpu 算子处理的结果之后再发送到下游。
现在的 gpu 的工具体系,例如 nsight全家桶,PyTorch Profiler都偏向研发态,在问题场景可复现的情况下,开启更细力度的记录,排查细节问题。在线上运行态我们会遇到一些不好复现的问题,都是当前环境下引发的。例如:
cpu 瓶颈,导致算子没抢到 cpu下发。
io,网络瓶颈,导致没走到算子流程。
环境或者发版,导致线上运行和实际代码有差异。
这些问题不一定需要研发去排查解决,通过一些部署编排就能解决。
上述问题在 cpu 场景下是相对完善的,有成熟的 oncpu,offcpu采样。我们的思路是在现有的 cpu 工具体系下融合 gpu 的算子。这样就完全可以复用原来的分析方法论。
下面我们重点围绕GPU特点和实现方案展开。
gpu特点
gpu和 cpu 属于异构。cpu 侧调用算子,其实是打包下发指令给 gpu,这里是异步的流程。我们无法通过 cpu 侧的调用来了解 gpu的运行情况。
这里我们可以用 gpu 侧提供的暴露能力,cupti来把数据暴露,在 cpu 侧做拼接。整体运行的时间线如下:
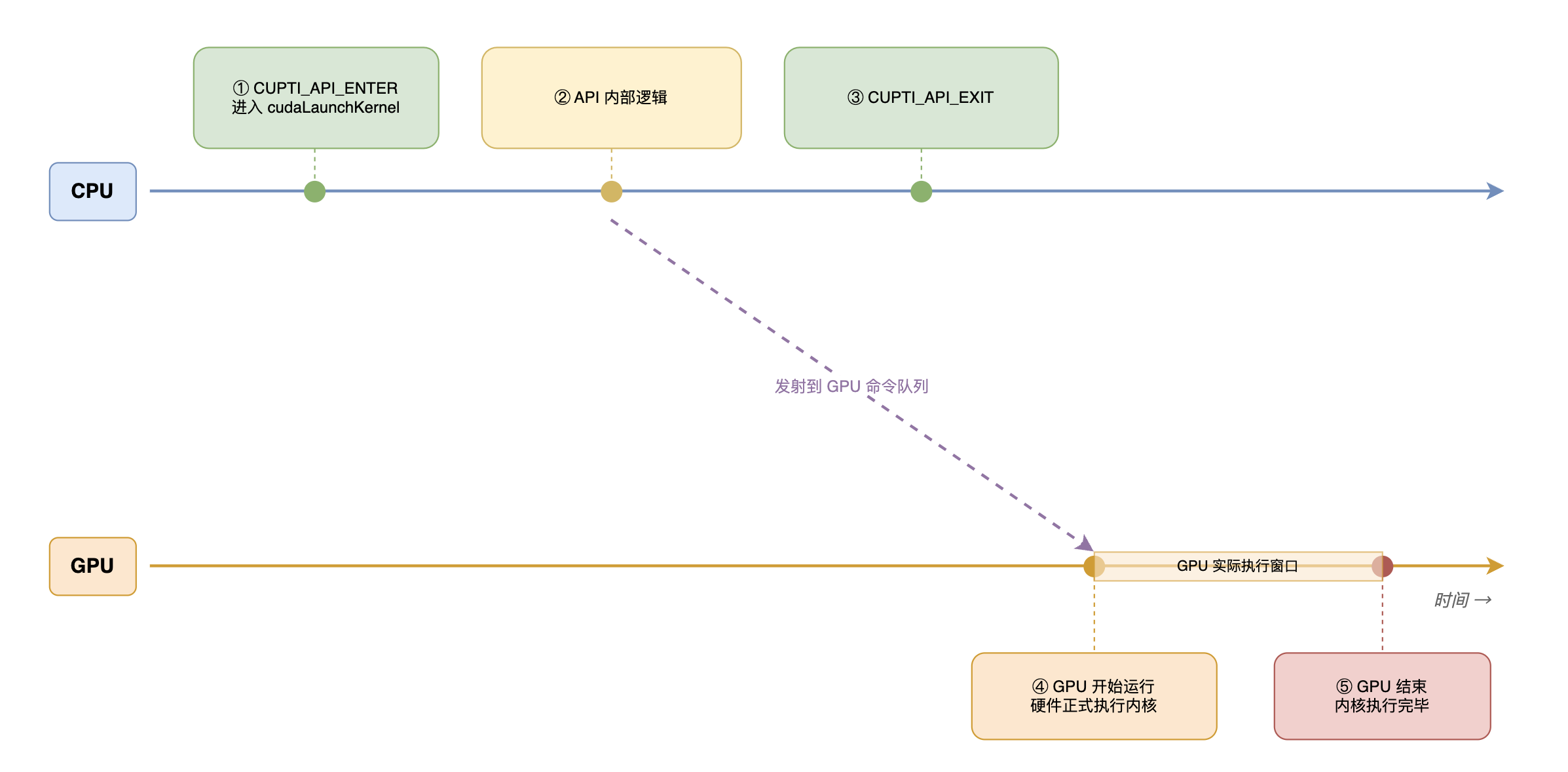
围绕 cupti 的实现方案,重点就是观测事件、完成异步事件的记录拼接、融合到 cpu采样。
实现方案
观测事件
依据上图,我们要观测 2 种事件。
第一种事件是 cpu侧调用的事件,重点用于栈回溯,这样就知道是哪个方法栈调用的算子。
第二种事件是异步完成事件,算子真正执行完的时间。
这里正好用到了 cupti 的 2 种 api。
第一种是Callback API,用于记录 cpu调用事件。
一段简单的样例代码如下:
void CUPTIAPI myCallback(void *userdata, CUpti_CallbackDomain domain,
CUpti_CallbackId cbid, const CUpti_CallbackData *cbInfo) {
// 检查是否为内核启动 API
if (cbid == CUPTI_RUNTIME_TRACE_CBID_cudaLaunchKernel_v7000 ||
cbid == CUPTI_RUNTIME_TRACE_CBID_cudaLaunch_v3020) {
// 在 API 进入阶段获取 ID
if (cbInfo->callbackSite == CUPTI_API_ENTER) {
uint32_t corrId = cbInfo->correlationId; // 此时 CPU 侧已获得该 ID
printf("Kernel Launch Correlation ID: %u\n", corrId);
}
}
}
CUpti_SubscriberHandle subscriber;
CUPTI_CALL(cuptiSubscribe(&subscriber, (CUpti_CallbackFunc)MyCallback, NULL));
CUPTI_CALL(cuptiEnableCallback(1, subscriber, CUPTI_CB_DOMAIN_RUNTIME_API,
CUPTI_RUNTIME_TRACE_CBID_cudaLaunchKernel_v7000));
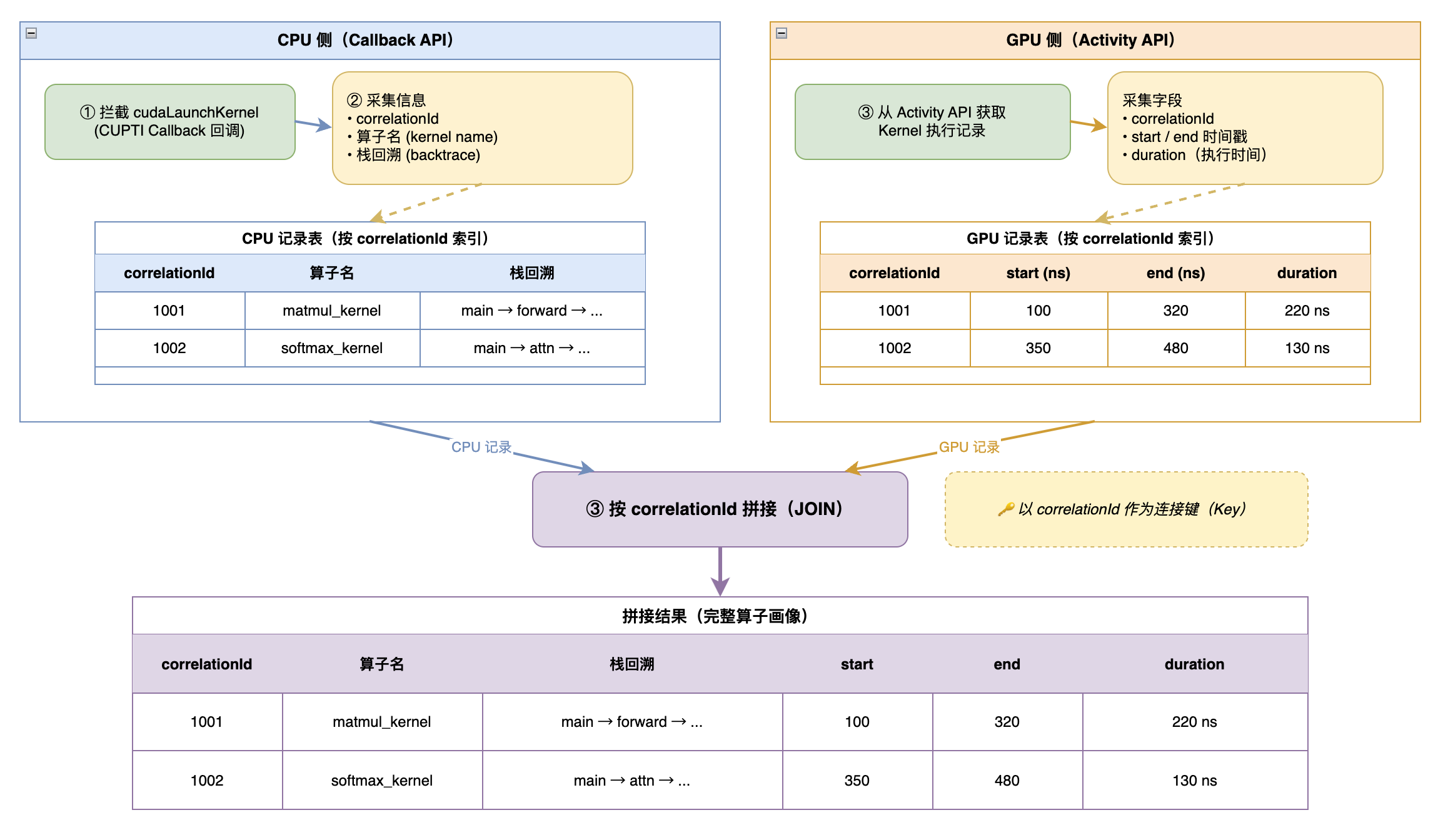
我们订阅了cudaLaunchKernel。代码调用cudaLaunchKernel的时候,会触发我们上面的myCallback,这里我们可以看到我们记录了correlationId。
CUPTI 在 CPU 调用 CUDA API 时隐式生成一个单调递增的 correlationId,这个 id相当于一次算子调用的唯一 id,用于后续获取到算子执行时间做拼接。
异步完成事件需要利用Activity API来获取。
void CUPTIAPI bufferCompleted(CUcontext ctx, uint32_t streamId, uint8_t *buffer, size_t size, size_t validSize) {
CUpti_Activity *record = NULL;
CUptiResult status;
while ((status = CUpti_ActivityGetNextRecord(buffer, validSize, &record)) == CUPTI_SUCCESS) {
if (record->kind == CUPTI_ACTIVITY_KIND_CONCURRENT_KERNEL ||
record->kind == CUPTI_ACTIVITY_KIND_KERNEL) {
auto *kernel = (CUpti_ActivityKernel4 *)record;
// 获取执行时间(纳秒转微秒)
double duration_us = (kernel->end - kernel->start) / 1000.0;
std::cout << "算子名称: " << kernel->name << std::endl;
std::cout << "执行时间: " << duration_us << " us" << std::endl;
// 关键:打印 Correlation ID
std::cout << "关联 ID (Correlation ID): " << kernel->correlationId << std::endl;
std::cout << "GPU Start: " << kernel->start << " ns" << std::endl;
}
}
free(buffer);
}
cuptiActivityRegisterCallbacks(bufferRequested, bufferCompleted);
cuptiActivityEnable(CUPTI_ACTIVITY_KIND_CONCURRENT_KERNEL);
Activity API需要一个 buffer 来读取数据。我们可以拿到已经执行完成的算子名称,执行时间和关联的 id。
上述的 2 个功能,都包装成 usdt,让 ebpf 可以挂在读取。
记录拼接
这里按照时间来进行拼接,不要按照 ebpf 程序接收到的顺序,当算子执行很快的时候,我们可能先收到Activity API返回的事件,后收到Callback API的结果。
融合cpu采样
这一步重点统一时间,cpu 采样是有采样频率的,根据频率直接换算成时间,offcpu 本来就是时间,cupti 的结果也是时间,处理和 offcpu一样即可。最后把数据统一转换成火焰图即可。
总结
经过上述的步骤,我们就把算子执行的过程拼接到了火焰图中。
用到了 cupti的Callback API和Activity API,获取数据后拿correlationId进行拼接。
看到结尾的同学好像发现了我上述没写如何低损耗的过程。这里一样复用了 cpu侧的方式:采样。在Callback API侧按比率丢弃数据,这样就减少了cupti代码本身的 cpu 消耗量了。