背景
用户发现 java 进程内存在持续增长,通过 pmap查看到了大量接近 64m 的内存块,判断为 glibc 的问题导致了内存增长,修改MALLOC_ARENA_MAX 重启进程。运行一周后发现内存持续增长现象还在,尝试更换分配库依旧无效,最后通过抓取分配确认问题为特殊条件下代码的内存泄漏,修复后稳定运行。
上述的情况中把 64m 内存块和glibc 的分配碎片问题做因果相关,导致了内存问题排查方向出现错误,基于第一版结论后续问题的重新排查和观测需要耗费更多的精力。
想要准确的排查这种问题,需要理解如下问题
glibc 的内存碎片是如何触发的
内存碎片和64m 内存块是什么关系,为什么有人会用64m 现象成功排查出问题。
jdk21 之后,jdk提供了哪些能力能准确的判断 glibc 碎片。
小测试
这里提供 3 种 pmap 的片段,大家可以判断一下是否存在内存碎片。 下文会揭示答案。
片段 1
00007f76a8021000 65404 0 0 ----- [ anon ]
片段 2
00007efb70000000 2056 2056 2056 rw--- [ anon ]
00007efb70202000 63480 0 0 ----- [ anon ]
00007efb74000000 2056 2056 2056 rw--- [ anon ]
00007efb74202000 63480 0 0 ----- [ anon ]
片段 3
00007fed88000000 65536 65528 65528 rw--- [ anon ]
00007fed8c000000 65536 65532 65532 rw--- [ anon ]
00007fed90000000 63840 63840 63840 rw--- [ anon ]
glibc内存碎片和 64m 现象
我们glibc问题合并在一起解释。下面先解释一下这两个现象。
内存碎片
用户在调用 free 函数后,glibc 内存分配器ptmalloc并不会立马归还操作系统,而是用空闲列表管理起来,以便后续复用,当释放的内存不和 top chunk 相邻,就无法归还给操作系统,最终形成了长期占用的内存碎片。
glibc 64m现象
linux 64 位系统下,由于 glibc 的内存分配器 ptmalloc 为了减少多线程竞争而引入的 Arena机制,导致进程虚拟内存出现大量 64MB 连续区块的现象。
上面的描述提到了很多概念,先留个印象,我们下面会解释。
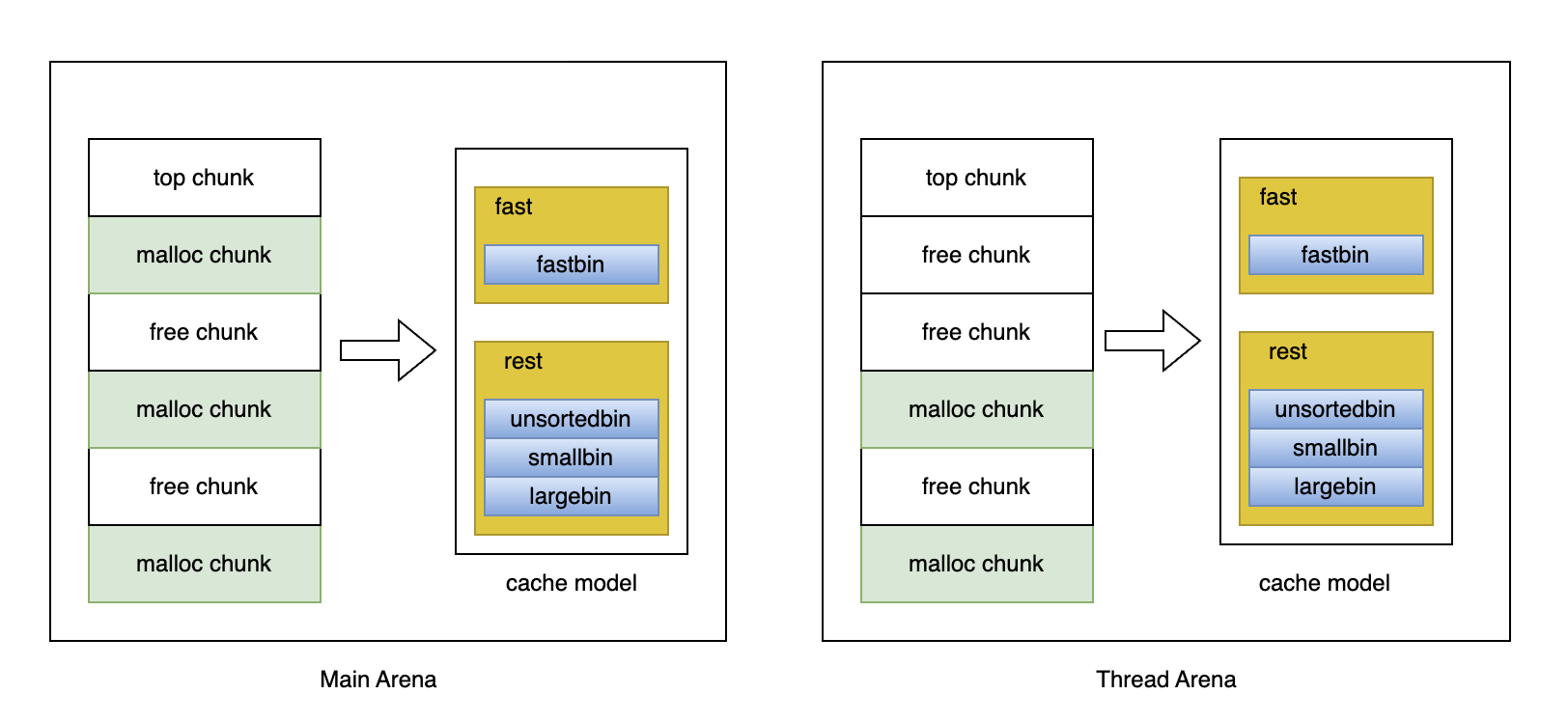
上图是一个精简的 glibc 的内存管理图。我们先看 Main Arena这边。
函数调用 malloc 的时候,Arena中会提供对应的内存,最开始分配的时候就是直接创建 malloc chunk(绿色部分),top chunk 会一直增长。当有缓存的时候,就可以直接从缓存中拿出现成的内存。
函数调用 free 的时候,会把程序拿到的 chunk 缓存起来,对应cache model。这是一个性能的优化方式,如果每次都是归还操作系统,下次再申请,这也是一种损耗,例如你释放了 5k 内存,又申请了 5k 内存,肯定考虑是上次的不释放,下次申请的时候把上次的地址拿出来。
缓存可以归为两类。就是图上的 fast 和 rest。里面蓝色的部分就不展开描述了,主要是根据chunk 的生命周期,内存的大小进行管理。
缓存带来的好处是不用频繁的和系统交互,坏处就是缓存命中不了的时候,缓存就浪费了。浪费的情况有如下 2 种
大小不匹配。 malloc 5k 的内存,缓存里只有 1 个 1k 和 1 个3k,这时候只能创建一个新的 malloc chunk。
大小匹配,地址不连续。Main Arena图上 2 个 free chunk 中间还有一个被占用的 malloc chunk。malloc 5k 的内存,缓存里只有 1 个 1k 和 1 个4k,这时候因为地址不连续,也不能合并成一个 5k 内存。
缓存既然有浪费的情况,那什么情况可以释放掉部分呢。需要 free chunk 和 top chunk 相邻。看 thread Arena,突然的 free chunk 和 top chunk 是相邻的,这个是可以释放相邻的 2 个 free chunk。Main Arena种和top chunk 相邻的是malloc chunk,无法释放底下的 free chunk。在程序不继续分配的情况下,只要top chunk 相邻malloc chunk,下面有多少个 free chunk 就会浪费多少内存。这就是 glibc 的内存碎片,进程的内存碎片就是所有Arena碎片的总和,等用所有Arena中 rest、fast缓存的累加。
那有多少Arena呢,这里就和 64m现象有关系了。
现代程序都是多线程的,每个线程都可以申请内存,如果是同一个Arena必然是有加锁竞争的等待的,影响性能。Thread Arena就是为了减少竞争存在的,这部分申请内存的时候直接使用 mmap申请64m 内存。Main Arena只有一个,剩下都是Thread Arena,Arena总数默认为 8*core。
因为是 mmap 申请的内存,默认是懒加载的,只有用到的时候才会真正带来进程内存的增长,mmap 的特性就导致了 pmap 的时候 64m 会被切成2 块,一块是已经使用的,一块是还未使用的。
了解了实现方式后,我们再来看64m 和内存碎片的关系,只有一种情况下相关性很大,那就是64m 内存中存在大量碎片的时候。是否有碎片呢,pmap 是看不出来的。我们需要依赖 glibc 提供的能力来准确识别。
统计进程的碎片内存
glibc 提供了一个接口,可以查看到内存碎片的分布情况。
https://man7.org/linux/man-pages/man3/malloc_info.3.html
malloc_info 可以打印出内存的分配缓存情况。输出的结果是 xml 格式。我根据标签来做解读,标签是有嵌套的,含义是相同的,但是含义范围依赖上层标签。
<heap nr="0">
heap就是代表Arena,后面的数字代表Arena编号,0 是 main Arena。
<sizes>
<size from="17" to="32" total="64" count="2"/>
<size from="449" to="449" total="449" count="1"/>
<size from="1074801" to="1122065" total="2196866" count="2"/>
<unsorted from="273" to="1074865" total="3228229" count="5"/>
</sizes>
sizes内表示的是缓存细节的统计。
unsorted就是对应图上的unsortedbin 缓存。
from,to 是分桶统计法,表示内存区间。count是缓存的块数,total是总共的内存大小。
<total type="fast" count="8" size="272"/>
<total type="rest" count="10158" size="119809223"/>
total是进程整体统计,这里的 fast 和 rest 就是图上的缓存模块分类。count是缓存的块数,size 是内存总大小。这个标签就是我们期待的进程碎片数据。
这里需要注意,缓存的块数不等于free 的 chunk 数,地址相邻的 chunk 是可以合并成一个块的。
解决进程的内存碎片
内存碎片的解决上已经有非常成熟的解决方案了。这里简单列举三种。
替换分配库。不再使用 glibc,使用碎片更少的 jemalloc,tcmalloc 等等。
限制 arena 个数。可以通过环境变量MALLOC_ARENA_MAX修改。
主动调用 glibc 提供的释放函数malloc_trim。
malloc_trim 是有版本差异的。https://man7.org/linux/man-pages/man3/malloc_trim.3.html
Since glibc 2.8 this function frees memory in all arenas and in all chunks with whole free pages. Before glibc 2.8 this function only freed memory at the top of the heap in the main arena.
如果是 glibc 2.8以下版本只作用于main arena,并且只作用于 top chunk的顶端的释放。低版本不建议使用malloc_trim。
jdk21的改进
碎片观测
jdk 21把malloc_info内置到 jdk 里了,可以通过 jcmd 调用。
void MallocInfoDcmd::execute(DCmdSource source, TRAPS) {
#ifdef __GLIBC__
char* buf;
size_t size;
FILE* stream = ::open_memstream(&buf, &size);
if (stream == nullptr) {
_output->print_cr("Error: Could not call malloc_info(3)");
return;
}
int err = os::Linux::malloc_info(stream);
if (err == 0) {
fflush(stream);
_output->print_raw(buf);
_output->cr();
} else if (err == -1) {
_output->print_cr("Error: %s", os::strerror(errno));
} else if (err == -2) {
_output->print_cr(malloc_info_unavailable);
} else {
ShouldNotReachHere();
}
::fclose(stream);
permit_forbidden_function::free(buf);
#else
_output->print_cr(malloc_info_unavailable);
#endif // __GLIBC__
}
代码比较直接,就是在 jdk 里调用malloc_info,jcmd 新增一个System.native_heap_info触发上述代码。
jcmd <pid> System.native_heap_info
我们就可以看到如下的输出结果了
<total type="fast" count="0" size="0"/>
<total type="rest" count="6414" size="14282942"/>
碎片解决
malloc_info都内置了,malloc_trim 也一样了。
我们可以通过System.trim_native_heap触发。
jcmd `pidof java` System.trim_native_heap
Trim native heap: RSS+Swap: 1071M->940M (-131M)
也可以通过设置定时间隔调用malloc_trim。
[0.025s][info][trimnative] Periodic native trim enabled (interval: 2000 ms)
[0.026s][info][trimnative] Native heap trimmer start
[2.031s][info][trimnative] Periodic Trim (1): 756M->753M (-2880K) 4.910ms
[4.038s][info][trimnative] Periodic Trim (2): 1271M->1267M (-3744K) 7.053ms
[6.045s][info][trimnative] Periodic Trim (3): 1397M->1392M (-4496K) 7.293ms
这个调用一旦执行就无法终止,建议调用前先测试一下,执行时间。
小测试答案
pmap 第三列才是 res,第二列是内存长度。
片段 1
00007f76a8021000 65404 0 0 ----- [ anon ]
这里res 是 0 ,说明对应的 arena 没有实际的内存分配。不是碎片问题。
片段 2
00007efb70000000 2056 2056 2056 rw--- [ anon ]
00007efb70202000 63480 0 0 ----- [ anon ]
00007efb74000000 2056 2056 2056 rw--- [ anon ]
00007efb74202000 63480 0 0 ----- [ anon ]
这里是arena 分配了 2m,剩下 62m 没分配的情况,内存的懒分配实际分配就 2m,随着占用,上面的数值会越来越大。实际内存占用很小,也不是碎片问题。
片段 3
00007fed88000000 65536 65528 65528 rw--- [ anon ]
00007fed8c000000 65536 65532 65532 rw--- [ anon ]
00007fed90000000 63840 63840 63840 rw--- [ anon ]
这个片段的arena分配使用了 64m,有内存碎片的可能性,但不知道比率有多大。这里得用上文的排查方式继续排查。