背景
heapdump 分析 是 java 堆内存泄漏常见的方法。以 mat 为例,这种分析方法有如下的限制。
有内存要求。mat 的内存一般为 heapdump 文件的 1.5 倍,低于这个比率有概率 mat 自身 OOME。
分析时间和对象数成正比。mat 为每个对象做索引计算支配树,对象越多分析时间越长。笔者300g 的heap 分析跑了 30 多个小时。
mat 实现本身依赖了long 数组,当对象数超过 java 数组的上限时,会报 OOME。官方的解决方案为设置对象丢弃。
这里展示一下第三点的报错信息,mat并不会在错误中直接推荐你配置丢弃对象。当遇到如下错误的时候,就可以去修改配置了。报错信息还是OutOfMemoryError,遇到很多同事都是直接增加 heap 内存重跑,这里是 jvm 限制,无法通过加资源来解决。
``
java.lang.OutOfMemoryError: Requested length of new long[2,147,483,640] exceeds limit of 2,147,483,639.
基于上面的限制下,heap一旦超过百 G,分析的时间成本就会直线飞升。
大内存空闲的机器不能立马到位。dump 属于低概率事件,时刻准备大内存机器有点资源浪费。
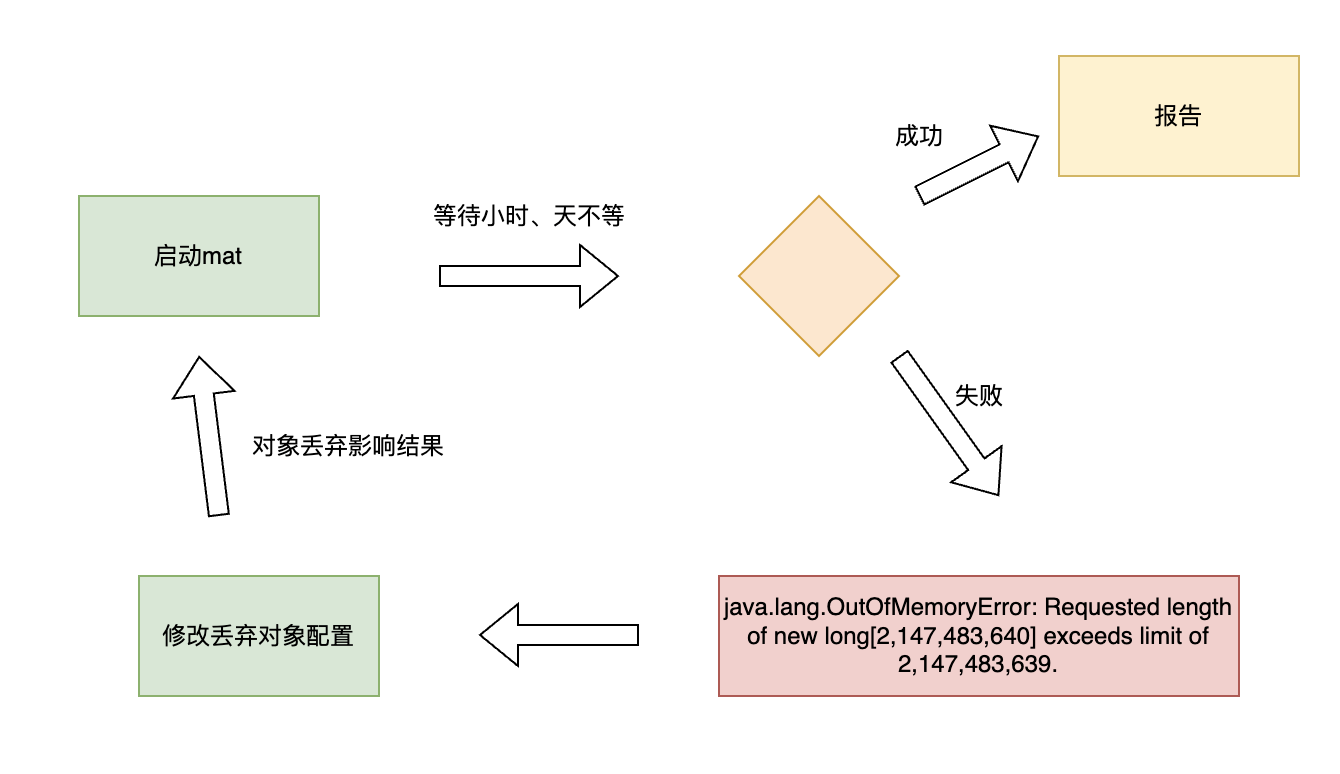
丢弃对象配置,无法特别准确设置。一方面是要保证对象数要低于21.47 亿,一方面还有保证丢弃完之后分析结果还能指导解决问题。这里往往需要多次尝试,每次尝试都有时间成本,例如 上面 300g 的 dump,跑了 5h 才报错。从开始分析到最终结果花了 3 天时间。
时间浪费在了下图的流程中。
今天介绍的方案很好的缩减了问题排查时间,是一种基于对象采样的方案。因为是采样,分析的方式没有 heapdump 那么直接。没到百 G 的 heap,还是建议继续走 MAT的方案。这个采样依赖 jdk 的OldObjectSample。
OldObjectSample
利用采样的方案来解决内存泄漏有 2 个难点
采样的结果如何来指导排查内存泄漏,毕竟样本丢失影响分析结果。
采样个数是有限的,如何实现均匀采样。
带着这 2 个问题,我们来了解一下OldObjectSample。
认识OldObjectSample
OldObjectSample是 jfr的一个采样事件,事件声明如下
<event name="jdk.OldObjectSample">
<setting name="enabled" control="old-objects-enabled">true</setting>
<setting name="stackTrace" control="old-objects-stack-trace">false</setting>
<setting name="cutoff" control="old-objects-cutoff">0 ns</setting>
</event>
不同 jdk 版本有默认配置的差异,这里使用之前可以检查一下,保证上面 2 个配置都是 true,第一个是开关配置,第二个是对象生成的堆栈配置。
修改后可以直接启动配置或者 jcmd 动态开启。这里使用和 jfr 没有区别。在 dump 出 jfr 文件的时候需要额外加一个配置。
path-to-gc-roots=true
这个配置会把采样对象的 gc root 也收集起来。这里获取 gc root 肯定伴随着 STW,使用时记得评估影响。
数据收集到之后我们可以用 jmc 进行分析,在活动对象面板中主要分析OldObjectSample事件。如果没有下载 jmc 也可以用 jfr 命令进行分析。
jfr print --events OldObjectSample x.jfr
这里可以看看这个事件的组成。
jdk.OldObjectSample {
startTime = 17:57:03.783
duration = 81.587 ms
//对象分配的时间
allocationTime = 17:56:58.228
//对象分配内存大小
objectSize = 4.0 MB
//存活时间
objectAge = 5.555 s
//对象记录之前的堆大小
lastKnownHeapUsage = 141.3 MB
//对象
object = [
byte[4194304]
[2] : java.lang.Object[10]
elementData : java.util.ArrayList Size: 5
list : java.lang.Class Class Name: TestLeak
]
//数组有这个属性
arrayElements = 4194304
//gc root
root = {
description = "Thread Name: Thread-0"
system = "Threads"
type = "Stack Variable"
}
eventThread = "Thread-0" (javaThreadId = 25)
//分配堆栈路径
stackTrace = [
TestLeak.lambda$main$0(ConcurrentSkipListMap) line: 18
TestLeak$$Lambda.0x0000000095040210.run()
java.lang.Thread.runWith(Object, Runnable) line: 1487
java.lang.Thread.run() line: 1474
]
}
上面有几个指标需要额外解释,和命名少有差异
objectAge并不是说对象经历了多少次 gc,只是表示存活时间。
Tickspan object_age = Ticks(_start_time.value()) - sample->allocation_time();
lastKnownHeapUsage并不是 jfr dump时的堆内存大小。而是采样时之前 一次 gc的内存大小。
sample->set_heap_used_at_last_gc(Universe::heap()->used_at_last_gc());
解决问题主要依靠的还是stackTrace(哪里产生的对象),root(哪里引用不能释放的),object(是什么对象)。从功能我们就可以回答上述第一个问题。
看到这里肯定会有疑问,既然是对象采样,为什么会有对象的分配堆栈?OldObjectSample看名字以为是老年带对象采样,这里的采样和事件的名字是一点都不匹配。我们从实现的角度再来理解一下这个事件的触发和采样机制。
OldObjectSample的实现
事件触发
OldObjectSample其实是基于分配的采样。如下图所示
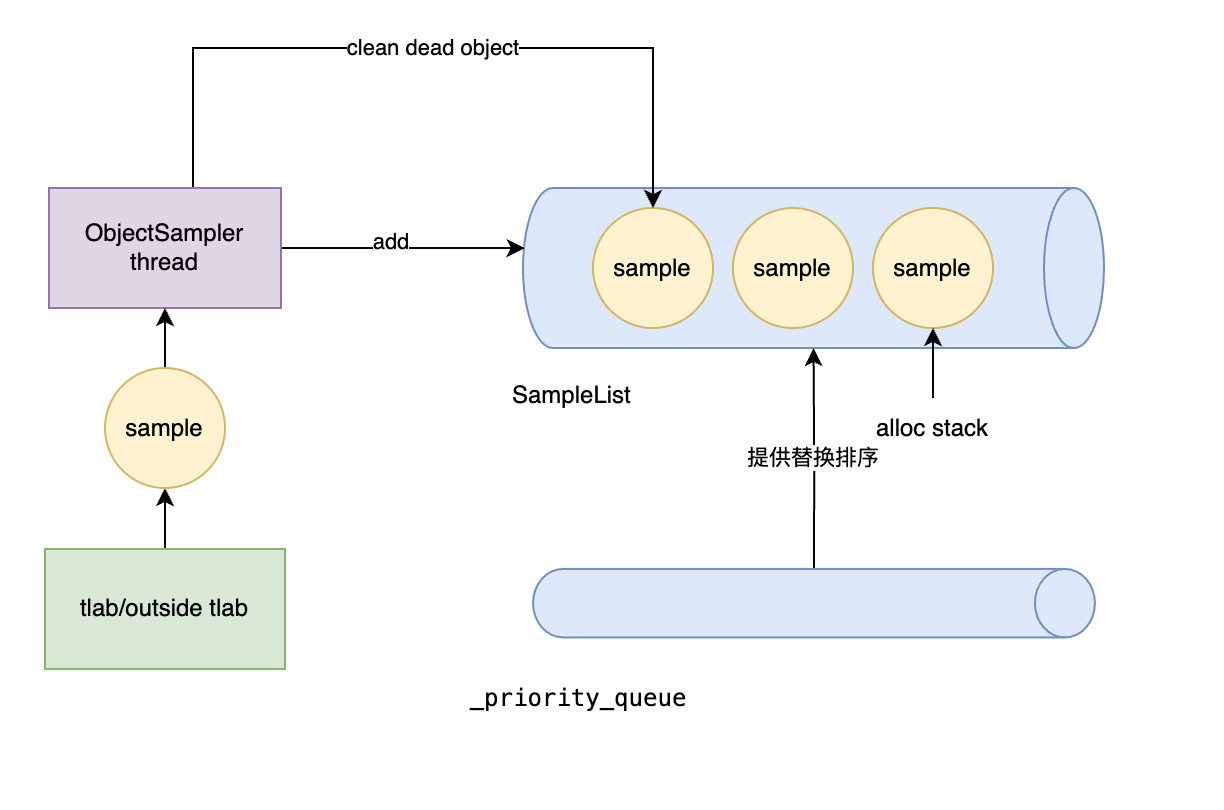
在 tlab和 outside tlab 的分配对象的过程中,把分配的对象放给了ObjectSampler thread处理。
JfrAllocationTracer::JfrAllocationTracer(const Klass* klass, HeapWord* obj, size_t alloc_size, bool outside_tlab, JavaThread* thread) {
if (LeakProfiler::is_running()) {
LeakProfiler::sample(obj, alloc_size, thread);
}
JfrObjectAllocationSample::send_event(klass, alloc_size, outside_tlab, thread);
}
把对象加入到队列中去,每个 sample 对象都构建了弱引用,当对象被回收掉之后,就可以剔除队列,这样就保证了 dump 的时候只有活着的对象了。
void ObjectSample::set_object(oop object) {
assert(object != nullptr, "invariant");
assert(_object.is_empty(), "should be empty");
Handle h(Thread::current(), object);
_object = WeakHandle(ObjectSampler::oop_storage(), h);
}
通过这部分代码,我们就可以理解到这个分配堆栈是怎么获取到的。他的生效机制其实只对开启之后产生的对象生效。
这里对象分配很多,不可能所有的活着的对象都放在队列里,队列默认长度为256,想修改需要在程序启动的时候加如下配置,目前版本(jdk25)不支持动态的修改这个值。
old-object-queue-size=
对象采样
jdk 实现的过程引入 span 的概念,span 表示分配的长度间隔。
_total_allocated += allocated;
const size_t span = _total_allocated - _priority_queue->total();
当对象数不足队列长度时,就直接加入SampleList队列,SampleList是一个按照对象产生时间的插入的队列,同时加入到一个有限队列中,对象头总是最新的对象。当队列满了之后,采样的机制开始生效。先和最小的 span 进行对比,太小就直接不收集。_total_allocated是一直累加的,哪怕是小对象,也总会产生出一个大于_priority_queue中 span 的值。
const ObjectSample* peek = _priority_queue->peek();
if (peek->span() > span) {
return;
}
priorityqueue的最小值是要被剔除的,把新对象加入,这里会判断一下被剔除的ObjectSample是否为最新的对象,如果不是,需要把他的 span 传递给上一个节点。
push_span(previous, popped_span);
sample->set_span(span);
这样就保证了在队列中 span 的值差距是比较接近的。采样分布比较均匀。
用如下的示意图如,我们来看看队列的变化。
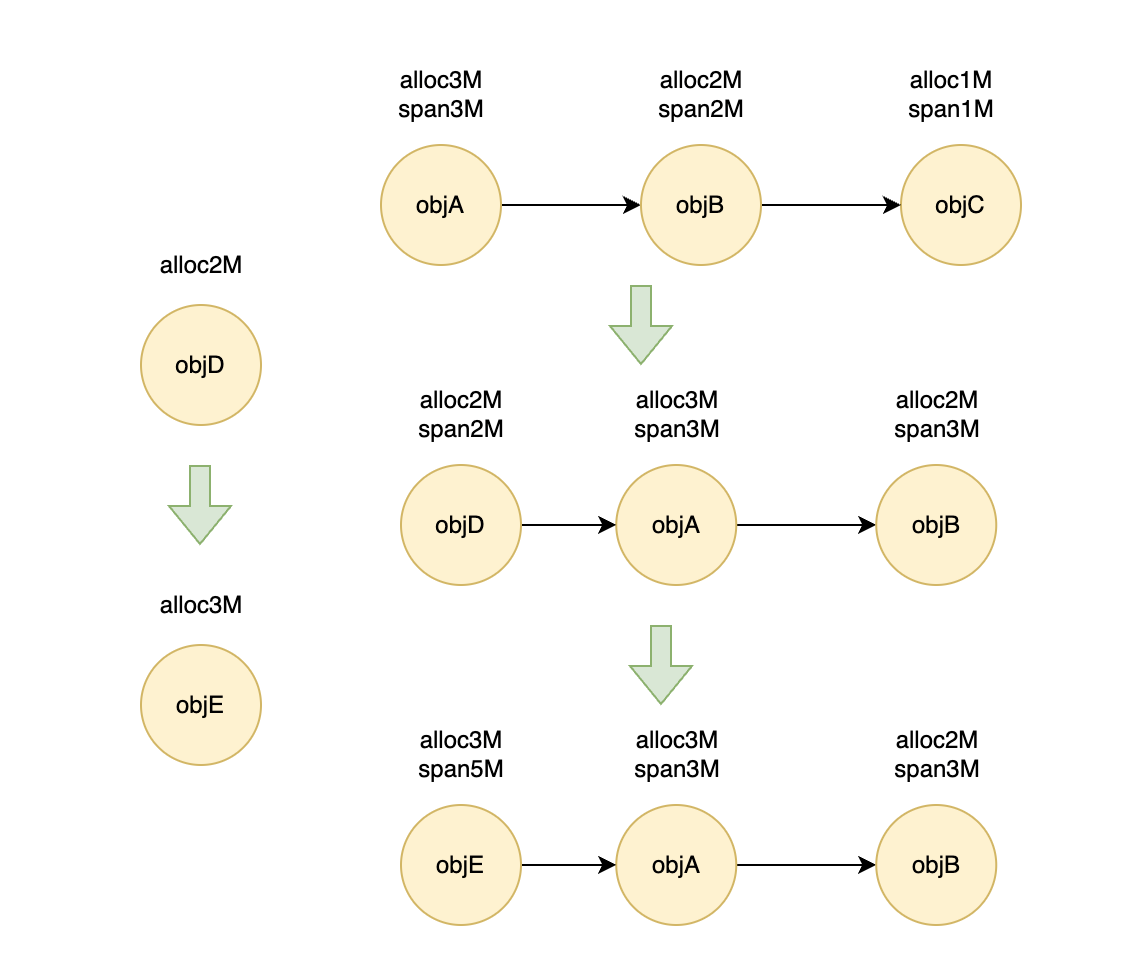
我们假设队列只能存放 3 个采样,D 申请 2M ,按照规则 span 计算也是2M,要大于 C,这里就会移除 C,并且把 C 的1M span 加到前一个节点 B 上。E 的加入,会直接替换 D,直接把D 的span 加到 E 即可。
最佳实践
通过上述的原理分析,大家肯定感觉似乎设计很有道理,但是基于传统的分析工具效果并不好。
这个功能上线之后,大家都是提前开启,录制很长的时间,这样每个分配事件都可以参与采样。并不知道采样的限制,如果对象有 3000 万存活,只采样 256,这个采样率太低了,根本无法指导问题解决。如果采样多个时间段,需要自己写个程序来分析,最终使用效果远不如 heapdump。
这个功能集成到 continuous profiling系统中,能发挥很大的作用。我们继续沿用设计的理念,持续采集一段时间,让 gc 发挥作用,去掉无效采样。这个时间一般设置为 5min。集成到 continuous profiling中,我们可以查看任意时间范围内对象的变化,结合指标系统,基本可以定位到泄漏的root 对象。